Detecting defects in brake boosters with machine learning
CETRI, that in STREAM-0D is in charge of data fusion, data sparsification and data-driven models, works closely with end-users to reduce the variability in the context of product performance so to better meet the requirements for suppliers.
For competitive enterprises in automotive sector, such as ZF – one of the end-users of the STREAM-0D project –, reaching zero-defects manufacturing is important. ZF is one of the world’s leading developer and supplier of active and passive automotive safety systems such as steering, braking and driver assistance systems.
In this article, CETRI presents how predictive analytics can aid the goal of STREAM-0D, by narrowing process control limits in favour of process capability at brake booster assembly lines.
A multi-step approach
CETRI received data from two production lines involved in the booster assembly in order to find out how the variability of the components in one of them affects the functionality of the final assembled booster, at the end of the other one. The performance of the booster is given by a number of key performance indicators, which are measured for each unit at the end of the assembly line.
Each indicator is accompanied by a range of tolerance given by the product specification. To detect product variation, CETRI built one data-driven model for each performance indicator using historical data. For the model building, input features from measurements at the first assembly line have been used. Before using them to build the models, a multi-step data cleaning process was developed to ensure the high quality of the data.
As a first step, CETRI correlated data from the two production lines by merging multiple datasets into a single one based on the tracking ID of the parts. Secondly, the variables of interest to be used as input features or target variables have been selected.
Subsequently, CETRI removed entries with missing values in any of the parameters of interest and made sure that no duplicates are present in the data. Outliers were detected and then removed. Lastly, the data were normalised (standardization, 0 mean, 1 standard deviation), so to be compatible with machine learning algorithms used to train the models.
Dataset have been the analysed, visualising and summarising the main characteristics of the features of interest. By plotting the univariate distributions of the features, CETRI found that some of them had zero variability and offered zero information regarding the dependent variables: those could be excluded from the analysis. Others showed very small variability.
Subsequently, CETRI performed a correlational analysis to investigate the relationships amongst input features and the relationships amongst input and output parameters. Only correlation values higher than 0.1 and lower than -0.1 have been plotted. For each data driven model analysed, CETRI found the most relevant values, which are:
- Jump-In data-driven model (DDM)
- Booster ratio DDM
- Leakage DDM
- Threshold DDM.
Particularly, for the last two mentioned DDMs, no significant features have been found.
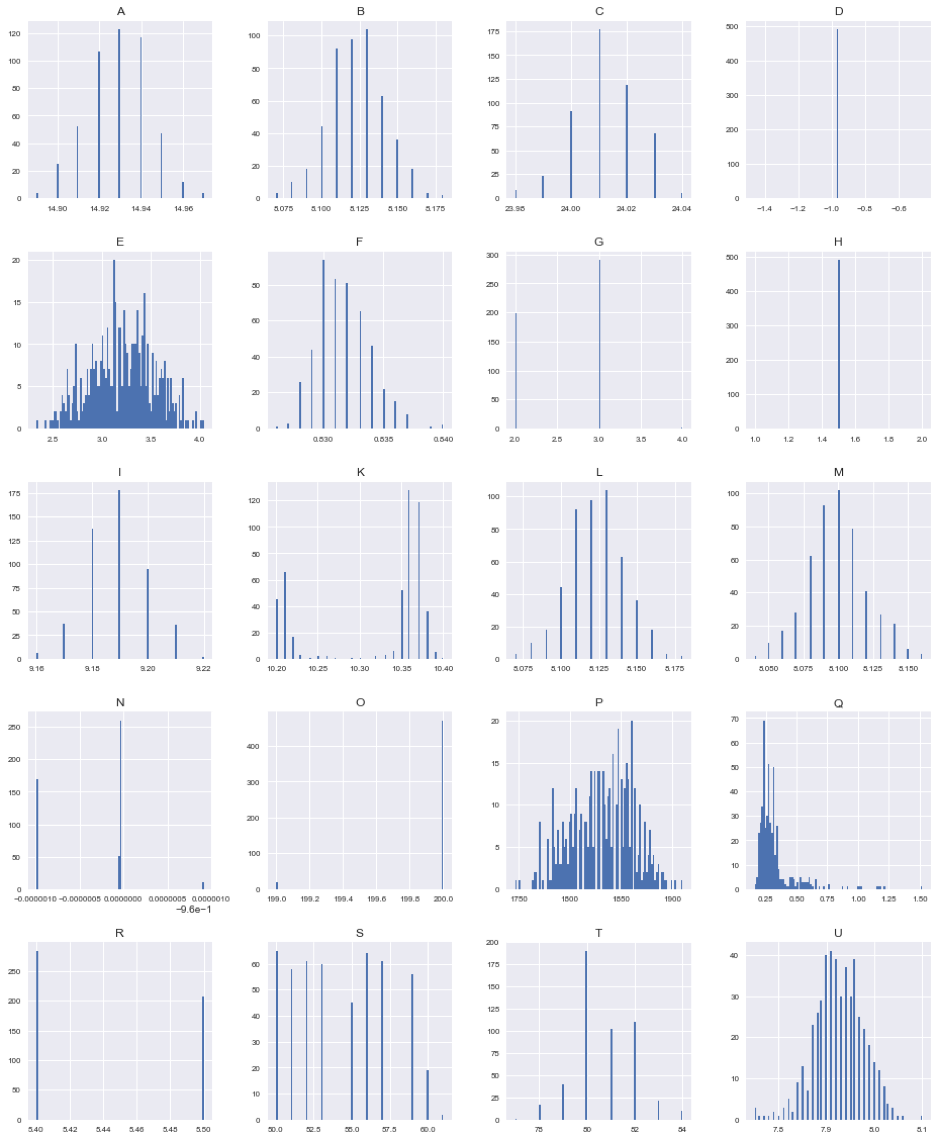
Figure 1 – Joint distributions along with the marginal distribution of the individual variables of interest, for the most relevant features.
The development of the Data-Driven Models
For the development of the data-driven models, CETRI used two different architectures:
- Deep Neural Networks (DNN)
- Random Forest Regressors (RFR)
To evaluate how well the data-driven models perform in situations not encountered before, CETRI reserved part of the data (30%) and used it for testing. The mean absolute error (MAE) for the developed data-driven model has been monitored.
It was now possible to get the forecasts of the models and test whether they fall into the range of tolerance and identify potential defects. The use of predictions can improve the flexibility of the manufacturing line. Such machine learning algorithms not only can detect defects faster than human operators can, but also predict them before they are even happening.
Moreover, they can identify minor subtleties and variations in the parts of the product that can cause defects that are otherwise difficult to detect. This work is currently in progress. Parameters are to be tuned to ensure the selection of models with the highest possible predictive power.
The finalised data-driven models will be integrated in the production line using an intelligent feedback loop process to correct machine failures in real-time, and thus ensure the elimination of defects in manufacturing of braking boosters.
—
This article by CETRI is part of the Bits of STREAM-0D series of contributions from the project’s consortium partners. Periodically, on STREAM-0D channels, a different topic will be given prominence, along with videos featuring members involved in the project.
Check Bits of STREAM-0D’s previous contributions from STREAM-0D partners:
- Ep. 1 – ITAINNOVA – “Simulation for zero-defects manufacturing”
- Ep. 2 – ITAINNOVA – “STREAM-0D End-users”
- Ep. 3 – DAY ONE – “Exploitation of a European project: how to start and key activities”
- Ep. 4 – LMS – “Industry 4.0 and zero-defects manufacturing: an insight on a new industrial era”
- Ep. 5 – IES – “Cloud data management: what is it all about?”
- Ep. 6 – ECN – “Reduced-Order Models, augmented knowledge”
- Ep. 7 – STAM – “Discrete manufacturing: model-based process optimization and control”
- Ep. 8 – Fersa Bearings – “Temperature influence in bearings manufacturing”
- Ep. 9 – Standard Profil – “STREAM-0D: prediction and self-adaptation in the extrusion process”
- Ep. 10 – ZF –“Artificial intelligence makes brake boosters fit for the future”
Follow STREAM-0D on: