Reducing bearing defects with predictive analytics
Within STREAM-0D solution, Data-Driven Models (DDMs) represent a crucial element to predict potential product defects; CETRI’s work is dedicated to the definition of DDMs. This article describes the tests carried out on Fersa Bearings line.
The Centre for Technology Research and Innovation (CETRI) help companies and public institutions to implement technological innovations and their timely launch to the market. CETRI is in close collaboration with companies and public institutions in the implementation of technological innovations area, enabling them to strengthen their competitive position over long-term.
Within the STREAM-0D project, CETRI leads data fusion, data sparsification and data-driven modelling activities. The main task is the construction of the data-driven database for efficient processing of data as well as minimised data transmission.
Fersa Bearings’ Data-Driven Models
Fersa Bearings is a Spanish multinational company devoted to the design, development, manufacturing and distribution of high-quality complete bearing solutions, with over 50 years of industry experience. In STREAM-0D, and in cooperation with the other partners, Fersa defines the industrial requirements and specifications for the implementation of simulation-based control in production lines for bearings.
The development of the data-driven models for Fersa required CETRI to build machine learning models for the prediction of potential product defects where machine parameters are used as inputs.
CETRI team developed multiple data-driven models, one for each of the following two machines: the ‘D1’ machine (Nova 9) and the dedicated one for the grinding of the inner bore diameter (Nova 11).
This allowed the team to associate machine parameters to desired outputs for each of the target’s variables. A list of input features and outputs is presented below:
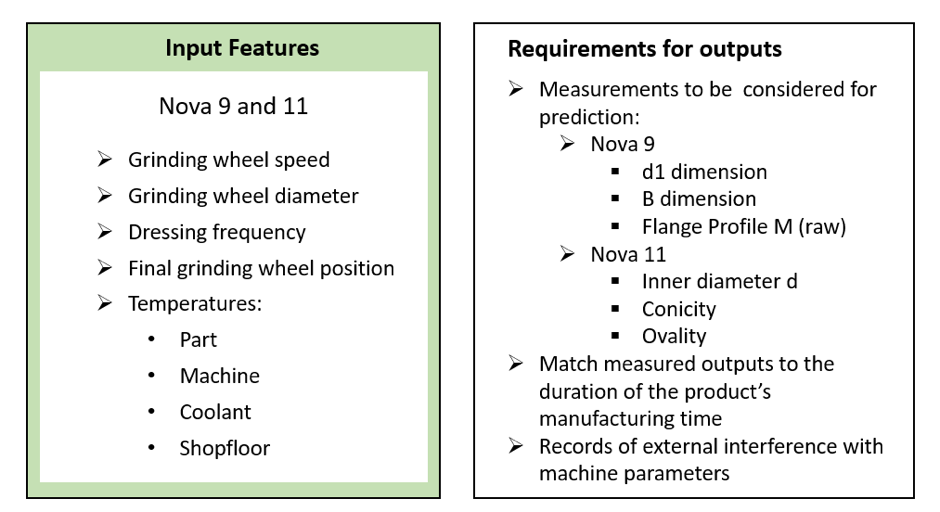
Regression and classification models have been developed; one model for simultaneous outputs and separate models for singular outputs.
Specifically, for Nova 9, three models have been developed for:
- D1 dimension
- B dimension
- Flange Profile M (raw).
Similarly, for Nova 11, three models have been developed for:
- Inner diameter
- Conicity
- Ovality
A multi-step data cleaning process was developed to ensure the high quality of the data, before using them to build the models.
Given the time-series nature of the output data, first the continuity of the data was ensured by filling in missing gaps and observations with fitted values, using polynomial approximations.
The variables of interest to be used as input features or target variables, have been then selected.
Subsequently, entries with missing values in any of the parameters of interest were removed and it was made sure that no duplicates were present in the data. Outliers were detected and then removed.
Lastly, data were normalised (standardization, 0 mean, 1 standard deviation), so they were compatible with the machine learning algorithms used to train our models.
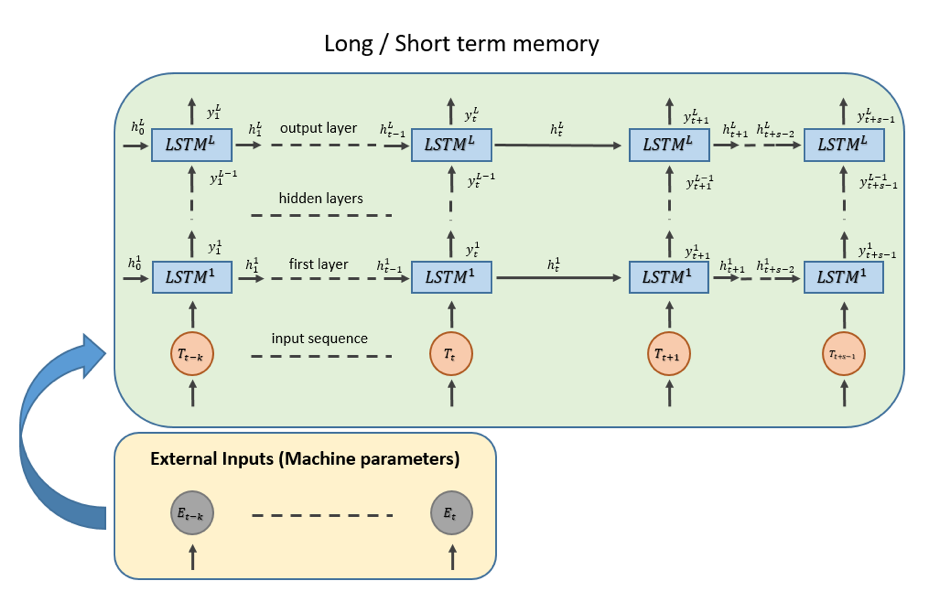
For the architecture of the model, CETRI team planned to use a combination of time-series and explanatory models. This enabled them to predict sequences of values for each target parameter given sample inputs and process parameters. More precisely, the team is planning to use deep recurrent neural networks using long-short term memory units.
Follow STREAM-0D on: